Meet Sonic-3.5 and Ink-2.
The #1 real-time speech and transcription models purpose-built for voice agents. One API, no tradeoffs between quality and speed.
Architecting AI that learns and interacts like humans
Frontier research, deployed in every conversation
Financial services

Real-time outbound verification calls on suspicious transactions, step-up authentication
Voice agents that improve customer experience, enhance security, and streamline operations across the financial ecosystem.







Voice agents that improve customer experience, enhance security, and streamline operations across the financial ecosystem.
Financial services
Voice agents that improve customer experience, enhance security, and streamline operations across the financial ecosystem.









Join the teams making the switch to Cartesia
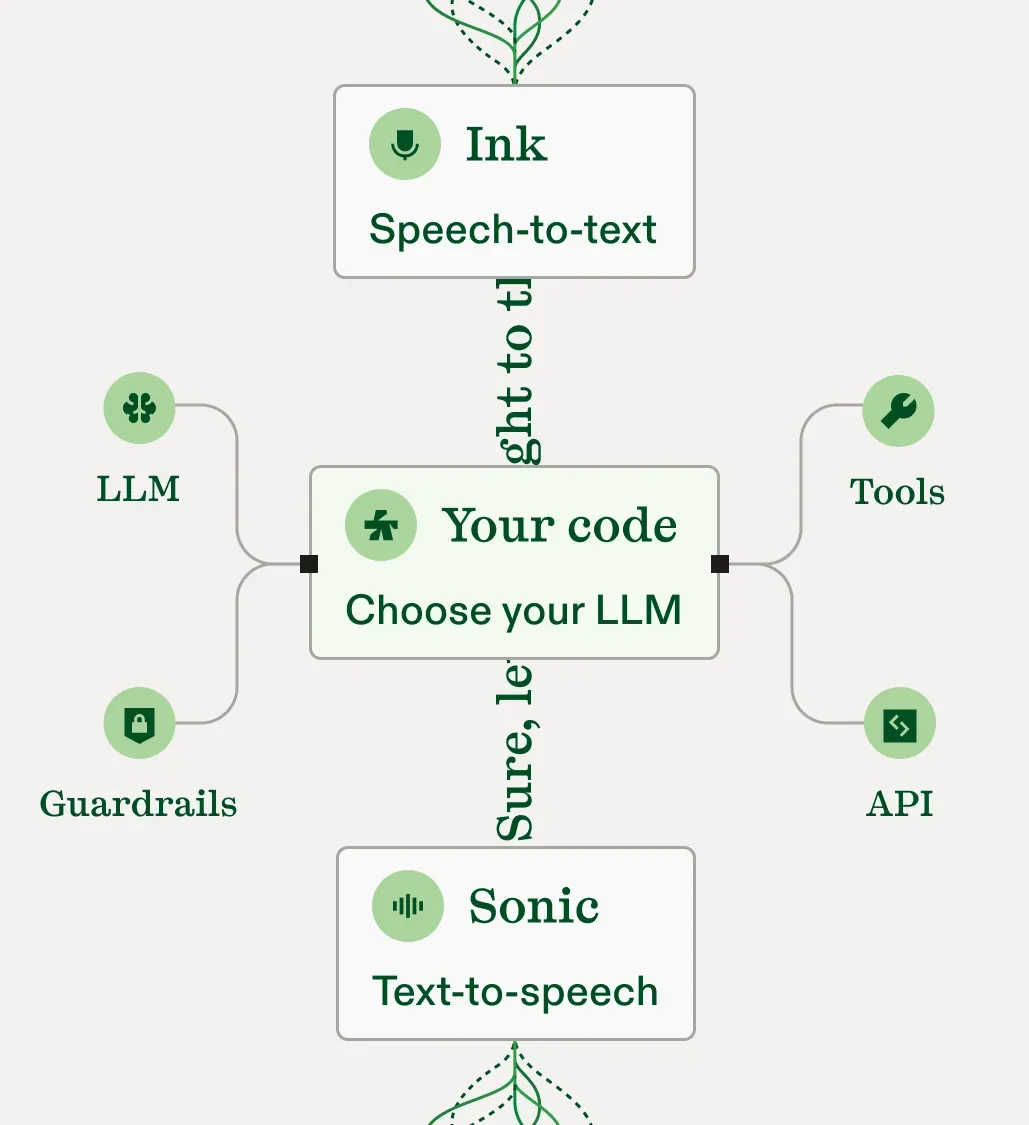
The full stack for interactive intelligence
Our models are designed for live interactions, built on State Space Models (SSMs), a new primitive for low latency, long-context reasoning, and greater efficiency at scale.
Voice agents as fast and accurate as the models powering them
Pioneering AI research: architectures that learn through interaction
Our team has pioneered breakthrough AI architectures, including state space models (SSMs), Mamba & H-Nets. Our research manifests our mission — we architect AI that learns from and interacts with the world like humans do.
Our research
Deploy AI anywhere.Own it everywhere.
The same models and agents across cloud, on-premise, and on-device. Inference runs in-region — keeping you within your latency envelope, data residency obligations, and compliance frameworks.





Get started today
Talk to an expert. Connect with a member of our team and learn how Cartesia can help you build world-class voice experiences.
Contact SalesStart building. Access our models via API and bring an agent into production with our robust SDKs and developer tools.
Try CartesiaWe’re hiring!
Build the future of interactive intelligence
Capabilities